
R 笔记:主成分和因子分析
若数据集变量过多,其中的交互关系可能很复杂。主成分分析和因子分析是两种用来探索和简化多变量复杂关系的常用方法,它们之间有联系也有区别。
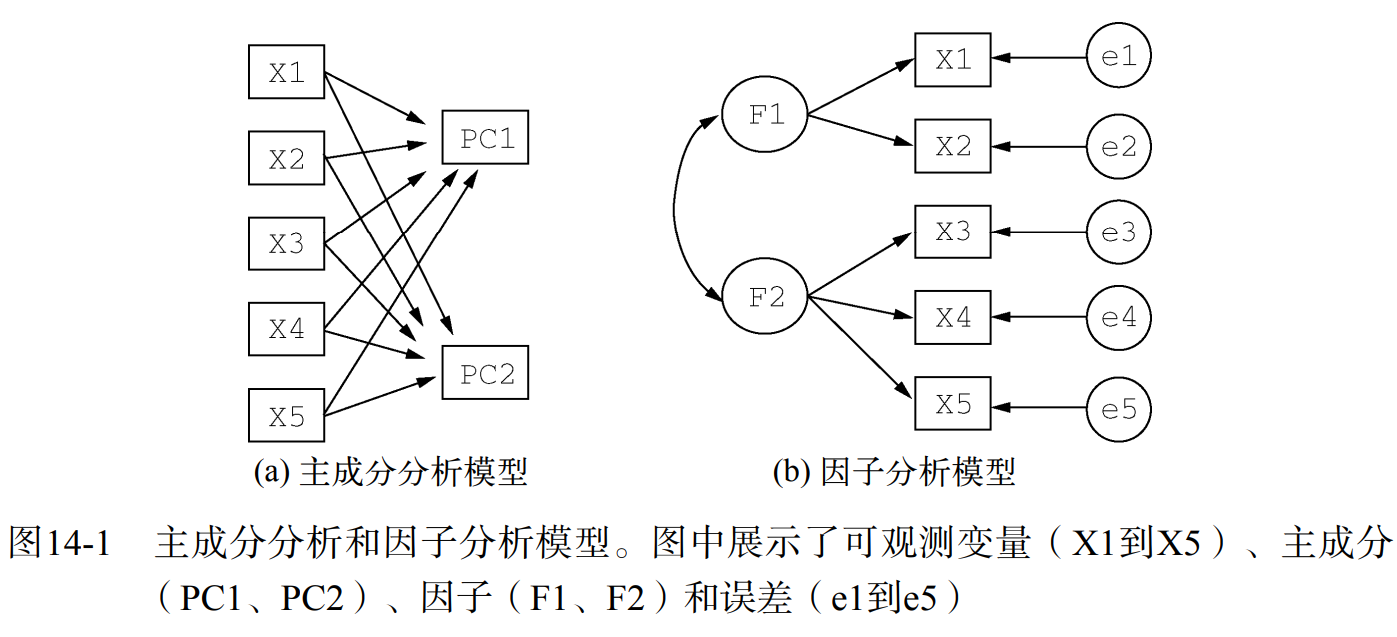
主成分分析(Principal Component Analysis,PCA),是一种数据降维技巧,能够将大量的相关变量转化为一组很少的不相关变量,即主成分。例如,使用 PCA 将 30 个相关的环境变量(可能冗余)转化为 5 个无关的成分变量,并且尽可能地保留原始数据集的信息。
主成分是对原始变量重新进行线性组合,将原先众多的,具有一定相关性的指标,重新组合为一组新的,相互独立的综合指标。PCA 的目标是用一组较少的独立变量代替大量相关变量,同时尽可能保留初始变量的信息,这些推到所得的变量称主成分,它们是观测变量的线性组合。如第一主成分为:
是 个观测变量的加权组合,对初始变量集的方差解释性最大。同理第二组成份 也是初始变量的线性组合,但对方差的解释性排第二,同时与 不相关。变量线性组合的权重由最大化各主成分的方差解释度来确定。其余的主成分以此类推,每一个主成分都最大化它对方差的解释程度,同时与其他所有主成分都不相关。因此理论上,可以选择和初始变量数相同的主成分,但并不实用。
R 中自带 princomp() 和 factanal() 函数可以进行 PCA 和 EFA,但功能比较简单。一般使用 psych 包中的函数代替。

主成分分析流程
主成分分析和因子分析的流程类似:
- 数据预处理:可以输入原始数据或相关系数矩阵,若输入初始数据,函数会自动计算相关系数矩阵
- 选择分析模型:判断是 PCA(数据降维)还是 EFA(潜在结构),若选择 EFA,还需要选择一种估计因子模型的方法
- 判断主成分/因子个数
- 选择主成分/因子
- 旋转主成分/因子
- 解释结果
- 计算主成分/因子得分
判断主成分个数
如何判断 PCA 中需要多少个主成分?以下是一些准则:
- 根据先验经验和理论知识判断个数
- 根据要解释变量方差的积累值的阈值来判断个数
- 通过检查变量间 的相关系数矩阵来判断个数
最常见的是基于特征值的方法。每个主成分都与相关系数矩阵的特征值相关联,第一主成分与最大的特征值相关联,第二主成分与第二大的特征值相关联,以此类推。Kaiser-harris 准则建议保留特征值大于 1 的主成分,特征值小于1的成分所解释的方差比包含在单个变量中的方差更少。Cattell 碎石检验则绘制了特征值与主成分数的图形。这类图形可以清晰地展示图形弯曲状况,在图形变化最大处之上的主成分都可保留。最后,还可以进行模拟,依据与初始矩阵相同大小的随机数据矩阵来判断要提取的特征值。若基于真实数据的某个特征值大于一组随机数据矩阵相应的平均特征值,那么该主成分可以保留。该方法称作平行分析。
利用 fa.parallel() 函数,可以同时对三种特征值判别准则进行评价,即 Kaiser-harris 准则、Cattell 碎石检验和平行分析。函数用法如下:
1 | fa.parallel(x, n.obs=NULL, fm="minres", fa="both", nfactors=1, n.iter=20) |
提取主成分
使用 principal() 函数可以根据原始数据矩阵或相关系数矩阵做主成分分析。函数用法如下:
1 | principal(r, nfactors=, rotate=, scores=) |
其中:
- r:相关系数矩阵或原始数据矩阵
- nfactors:设定主成分数(默认为 1 )
- rotate:指定旋转的方法(默认 varimax 最大方差旋转)
- scores:设定是否需要计算主成分得分(默认不需要)
主成分旋转
旋转是一系列将成分载荷阵变得更容易解释的数学方法,它们尽可能地对成分去噪。旋转方法有两种:
- 正交旋转:使选择的成分保持不相关
- 斜交旋转:使选择的成分变得相关
旋转方法也会依据去噪定义的不同而不同。最流行的正交旋转是方差极大旋转,它试图对载荷阵的列进行去噪,使得每个成分只是由一组有限的变量来解释(即载荷阵每列只有少数几个很大的载荷,其他都是很小的载荷)。
获得主成分得分
我们的最终目标是用一组较少的变量替换一组较多的相关变量,因此,还需要获取每个观测在成分上的得分。
实例
例 1:USJudgeRatings
psych 包中的 USAJudgeRatings 数据集包含了律师对美国高等法院法官的评分,包含 43 个观测,12 个变量。就可以使用 PCA 对这 12 个变量进行分析,提取出主成分。
1 | install.packages('psych') |
确定主成分个数
1 | fa.parallel(USJudgeRatings, fa='pc', n.iter = 100) |
结果如下

线段为基于观测特征值的碎石检验,虚线为根据 100 个随机数矩阵推导出来的特征值均值。三者均表明,只需保留一个主成分即可。
提取主成分
1 | pc <- principal(USJudgeRatings, nfactors = 1) |
此处,获取一个未旋转的主成分。由于PCA只对相关系数矩阵进行分析,在获取主成分前,原始数据将会被自动转换为相关系数矩阵。
PC1 栏包含了成分载荷,指观测变量与主成分的相关系数。如果提取不止一个主成分,那么还将会有 PC2、PC3 等栏。成分载荷(component loadings)可用来解释主成分的含义。第一主成分(PC1)与每个变量都高度相关(除了第一个),也就是说,它是一个可用来进行一般性评价的维度。
h2 栏指成分公因子方差——主成分对每个变量的方差解释度。u2 栏指成分唯一性——方差无法被主成分解释的比例(即 1-h2)。例如,体能(PHYS)80% 的方差都可用第一主成分来解释,20% 不能。第一主成分对 ORAL 变量的解释性最好,对 CONT 变量的解释性则最差。
SS loadings 行包含了与主成分相关联的特征值,指的是与特定主成分相关联的标准化后的方差值(本例中,第一主成分的值为 10)。最后,Proportion Var 行表示的是每个主成分对整个数据集的解释程度。此处可以看到,第一主成分解释了 12 个变量 84% 的方差。
获得主成分得分
只需加上参数 score=T 即可获得评分。
1 | pc <- principal(USJudgeRatings, nfactors = 1, scores = T) |
例 2:Harman23.cor
该数据集包含 305 个女孩的 8 个身体测量指标的相关系数,利用 pheatmap() 函数可视化如下:

同样,希望用较少的变量替换这些原始身体指标。
确定主成分个数
1 | fa.parallel(Harman23.cor$cov, n.obs = 302, fa='pc', n.iter = 100) |

三种准则均显示保留两个主成分,但要注意三个准则并不总是相同,需要根据实际情况提取不同数目的主成分,选择最优解。
提取主成分
1 | pc <- principal(Harman23.cor$cov, nfactors = 2, rotate = 'none') |
可见,第一主成分解释了身体测量指标 58% 的方差,第二主成分解释了 22% 的方差,二者一共解释了 81% 的方差。对于 height 变量,二者一共解释了 88% 的方差。
成分载荷显示,PC1 与所有变量都正相关,PC2 与前 4 个变量负相关,与其他变量正相关。当提取多个成分时,对其进行旋转可时结果更有解释性。
主成分旋转
1 | rc <- principal(Harman23.cor$cov, nfactors = 2, rotate = 'varimax') |
旋转后变为 RC,RC1 主要由前四个变量来解释,主要与高度相关;RC2 主要由后四个变量来解释,主要与容量相关。两个主成分仍不相关,对变量的解释性不变,这是因为变量的群组没有发生变化。另外,两个主成分旋转后的累积方差解释性没有变化(81%),变的只是各个主成分对方差的解释度(成分 1 从 58% 变为 44%,成分 2 从 22% 变为 37%)。各成分的方差解释度趋同,准确来说,此时应该称它们为成分而不是主成分(因为单个主成分方差最大化性质没有保留)。
获得主成分得分系数
当主成分分析基于相关系数矩阵时,不能获取每个观测的主成分得分,只能得到得分系数。
1 | round(unclass(rc$weights), 2) |
主成分得分可以由下式计算:
其中:
- 是 height、arm.span 等变量
- 是对应变量的值
上式都假定身体测量指标都已标准化(mean = 0, sd = 1)。注意,体重在 PC1 上的系数约为 0.3 或 0,对于 PC2 也是一样。从实际角度考虑,你可以进一步简化方法,将第一主成分看做是前四个变量标准化得分的均值,类似地,将第二主成分看做是后四个变量标准化得分的均值,这正是我通常在实际中采用的方法。
探索性因子分析(exploration factor analysis,EFA)的是一系列用来发现一组变量潜在结构的方法。目标是通过寻找一组更小的、潜在的活隐藏的结构来解释已知的观测变量。如高中的几门学科,用因子分析就是:语言能力(语、外)、逻辑推理(数、理、化、生)、逻辑分析(史、地、政)。重点在于如何解释观测变量,探索观测变量的结构和原因。模型形式为:
其中:
- :第 个可观测变量();
- :公共因子(),且 ;
- : 变量独有的部分(无法被公共因子解释);
- :可以认为是每个因子对复合而成的可观测变量的贡献度。
如 Harman74.cor 数据集包含 24 个心理测验间的相关系数,若用 EFA 分析,就是要找到能够解释这些变量的潜在因子。
二者的异同
相同点:
- 都对原始数据进行降维处理
- 都消除了原始指标的相关性对综合评价所造成的信息重复的影响
- 构造综合评价时涉及的权数具有客观性
- 在信息损失不大的前提下,减少了评价的工作量
不同点:
| PCA | EFA |
|---|---|
| 用较少变量表示原来的样本 | 用较少的因子表示原来的变量 |
| 目的:样本数据损失最小时,对原数据进行变量降维 | 目的:尽可能保持原变量相互关系,寻找变量的公共因子 |
| 参数估计,一般是求相关矩阵的特征值和相应的特征向量,取前几个计算主成分 | 参数估计,指定几个公共因子,将其还原成相关数据矩阵,在和原样本相关矩阵最相似度原则下,估计各个公共因子的估计值 |
| 举例:语、数、英、文科、理科(变量降维) | 举例:语言能力(语、外)、逻辑推理(数、理、化、生)、逻辑分析(史、地、政)(公共因子) |
实例
例 1:ability.cov
该数据集为 112 个参与者在 6 个测验(智力、画图、积木、迷津、阅读、词汇)得分的协方差矩阵。
1 | ability.cov |
将协方差矩阵转换为相关系数矩阵
1 | options(digits = 2) |
确定公共因子个数
1 | # 选择 both,以示 PCA 和 EFA 差别 |

× 是 PCA,显示保留 1 个(碎石检验和平行分析)或 2 个(特征值大于 1)主成分。这时候,通常高估因子比低估因子结果要好,因为高估因子数一般较少曲解“真实”情况。
△ 是 EFA,显示保留 2 个因子,前两个特征值都在拐角之上,且大于 100 次随机数矩阵的特征值均值。对于 EFA,Kaiser-Harris 准则的特征值大于 0 ,而不是 1,因此也符合。
提取公共因子
可以用 fa() 函数处理:
1 | fa(r, nfactors=, n.obs =, rotate=, scores=, fm=) |
其中:
- r:相关系数矩阵或者原始数据矩阵
- nfactors:设定提取的因子数(默认为1)
- n.obs:是观测数(输入相关系数矩阵时需要填写)
- rotate:设定旋转的方法(默认互变异数最小法)
- scores:设定是否计算因子得分(默认不计算)
- fm:设定因子化方法(默认极小残差法)
提取公共因子的方法有很多,包括最大似然法(ml)、主轴迭代法(pa)、加权最小二乘法(wls)、广义加权最小二乘法(gls)和最小残差法(minres)。统计学家青睐使用最大似然法,因为它有良好的统计性质。不过有时候最大似然法不会收敛,此时使用主轴迭代法效果会很好。
主轴迭代法示例(不旋转)
1 | fa(r=corr, nfactors = 2, rotate = 'none', fm='pa') |
可见,两个因子解释了 6 个心理学测验 60% 的方差,但因子载荷的意义不太好解释,需要对因子进行旋转。
最大似然法示例(不旋转)
1 | fa(r=corr, nfactors = 2, rotate = 'none', fm='ml') |
与上类似。
因子旋转
主轴迭代法 + 正交旋转
1 | fa(r=corr, nfactors = 2, rotate = 'varimax', fm='pa') |
此时因子更好解释,reading 和 vocab 在 PA1 的载荷较大,picture、blocks 和 maze 在 PA2 上载荷较大,而 general 智力测试在两个因子上的载荷较为平均。说明,存在一个语言的智力因子和非语言的智力因子。
最大似然法 + 正交旋转
1 | fa(r=corr, nfactors = 2, rotate = 'varimax', fm='ml') |
结果类似。
使用正交旋转将使两个因子不相关。如果允许两个因子相关呢?
主轴迭代法 + 斜交旋转
1 | # 斜交旋转需要 GPArotation 包 |
1 | fa(r=corr, nfactors = 2, rotate = 'promax', fm='pa') |
正交旋转侧重于因子结构矩阵(变量与因子的相关系数),而斜交旋转会考虑三个矩阵:因子结构矩阵、因子模式矩阵和因子关联矩阵。
因子模式矩阵即标准化的回归系数矩阵。它列出了因子预测变量的权重。因子关联矩阵即因子相关系数矩阵。PA1 和 PA2 栏即因子模式矩阵 (不是正交旋转中的因子结构矩阵),它们是标准化的回归系数,而不是相关系数。同样可以得到一个语言因子和一个非语言因子。
最下方的因子关联矩阵显示两个因子的相关系数为 0.55,相关性很大。如果因子间的关联性很低,可能需要重新使用正交旋转来简化问题。
因子结构矩阵(或称因子载荷阵)没有被列出来,可以使用公式 计算,其中 是因子载荷阵, 为因子模式矩阵, 为因子关联矩阵。
1 | fa.promax <- fa(r=corr, nfactors = 2, rotate = 'promax', fm='pa') |
现在你可以看到变量与因子间的相关系数。将它们与正交旋转所得因子载荷阵相比,会发现该载荷阵列的噪音比较大,这是因为之前你允许潜在因子相关。虽然斜交方法更为复杂,但模型将更符合真实数据。
使用 factor.plot() 或 fa.diagram() 函数,可以绘制正交或者斜交结果的图形。
1 | factor.plot(fa.promax, labels = row.names(fa.promax$loadings)) |

可见,词汇和阅读在 PA1 上载荷较大,而积木图案、画图和迷宫在 PA2 上载荷较大。普通智力测验在两个因子上较为平均。
1 | fa.diagram(fa.promax, simple=FALSE) |

若使 simple = T,那么将仅显示每个因子下最大的载荷,以及因子间的相关系数。这类图形在有多个因子时十分实用。
1 | fa.diagram(fa.promax, simple=TRUE) |
例 2:Harman74.cov
1 | fa.parallel(Harman74.cor$cov, n.obs = 145, fa='both', n.iter = 100) |

1 | fa.24 <- fa(Harman74.cor$cov, nfactors = 4, rotate = 'promax') |




